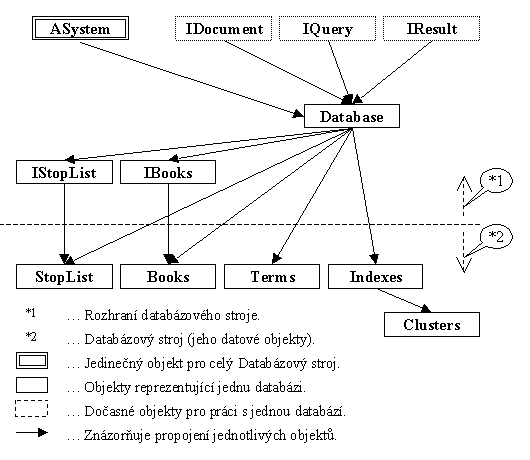
Obrázek 5.2.1-1 - zobrazení vztahu mezi databázovým strojem a rozhraním databázového stroje
| Obsah | Dal¹í | Pøedchozí |
Databázový stroj poskytuje své slu¾by (práci s daty, které jsou potøebné pro zaji¹tìní funkcionality celého dokumentografického informaèního systému) pro svou nadvrstvu, na kterou se v dal¹ím textu budeme odkazovat jako na rozhraní databázového stroje. Toto rozhraní implementuje znaènou èást logiky práce s daty poskytovanými databázovým strojem.
Po¾adavky kladené na databázový stroj vycházejí pøedev¹ím z potøeb námi navr¾eného modelu dokumentografického informaèního systému, pøesnìji z charakteru dat, které je nutné spravovat pro jeho bìh, a z vlastností operací nad danými daty. Jde pøedev¹ím o zaji¹tìní následujícího:
Pøi návrhu systému jsme uva¾ovali dvì následující mo¾nosti, jak zajistit vý¹e uvedené po¾adavky a tím nabídnout vy¹¹í vrstvì (pro rozhraní databázového stroje) odpovídající slu¾by:
S ohledem na specifické vyu¾ití navrhovaného databázového stroje se jevilo pou¾ití vlastních prostøedkù pro zaji¹tìní databázových slu¾eb efektivnìj¹í, jak na rychlost pøístupu k datùm, tak velikost s ohledem na vyu¾ití místa ve vnìj¹í pamìti. Na druhou stranu, pro pou¾ití ji¾ existujícího relaèního databázového stroje, zde mluvila mo¾nost vyu¾ití transakèních a bezpeènostních slu¾eb, které má ji¾ vìt¹ina produktù v sobì zahrnuta. V koneèné fázi bylo rozhodnuto o implementaci vlastního nástroje pro zaji¹tìní databázových (znaènì speciálních) slu¾eb pro vy¹¹í vrstvu. Systém Agent si v¹ak, díky svému modulárnímu rozdìlení, zároveò uchovává mo¾nost nahrazení námi implementovaného databázového stroje strojem relaèním èi jiným databázovým strojem. Jeho zaèlenìní do systému se zajistí úpravou implementace rozhraní databázového stroje, pomocí kterého komunikují vy¹¹í vrstvy. Vy¹¹í vrstvy jsou tedy na pou¾itém databázovém stroji nezávislé.
Obrázek 5.2.1-1 - zobrazení vztahu
mezi databázovým strojem a rozhraním databázového
stroje
Databázový stroj je implementován pomocí následujících základních tøíd:
Úkolem objektù typu StopList je správa termù obsa¾ených ve stoplistu jednotlivých databází. Jde pøedev¹ím o zaji¹tìní následujících základních operací:
Dal¹í po¾adavky kladené na objekty typu StopList vycházejí ze zpùsobu jejich pou¾ití. Ten klade dùraz pøedev¹ím na rychlost jednotlivých operací, které budou postupnì provádìny na datech (termech) tìchto objektù. Po provedení analýzy èetností výskytù jednotlivých operací, byl vznesen po¾adavek na rychlost pøedev¹ím u operace member a následnì také u operací insertTerm a deleteTerm. U operace getTerms není rychlost vy¾adována, nebo» se nejedná o operaci èastou v porovnání s ostatními operacemi.
Základní otázka, která se musela vyøe¹it pøed vlastní implementaci tøídy StopList, byla volba reprezentace dat. S ohledem na po¾adavky uvedené v pøedchozím odstavci, zde byly v zásadì dvì mo¾nosti. První z nich nabízela reprezentaci termù v podobì nìkteré ze stromových struktur. Druhou mo¾ností bylo pou¾ití he¹ování a he¹ovací tabulky. Hlavním kritériem pøi výbìru mezi tìmito mo¾nostmi, byla èasová nároènost po¾adovaných operací, pøedev¹ím v¹ak rychlost operace member . Z tohoto pohledu byla nakonec vybrána mo¾nost druhá, která nabízí konstantní èas operace member, oproti èasu logaritmickému poskytnutého první mo¾ností.
Vzhledem k pou¾ití he¹ování, bylo v poèáteèní fázi implementace nutné nalézt he¹ovací funkci, která by rovnomìrnì vkládala termy do he¹ovací tabulky. Za he¹ovací funkci byla zvolena funkce podobná funkci pou¾ité pro poèítaní kontrolních souètù (napø. v TCP/IP). Z dosavadních testù lze konstatovat, ¾e takto zvolená funkce splòuje po¾adavky co se týèe rovnomìrného rozprostøení he¹ovacích klíèù.
Co se týèe vlastní metody he¹ování, do¹lo v prùbìhu implementace tøídy StopList k její výmìnì. V prvním "kole", bylo pou¾ito he¹ování dle konstantního poètu bitù he¹ovacího klíèe he¹ovaného záznamu. Kolize (pøeteèení blokù slou¾ících pro ukládaní záznamu stejných klíèù) byly øe¹eny pomocí vytváøení spojových seznamù nových blokù. Nevýhodou této metody bylo, ¾e ji¾ pøi vytváøení he¹ovací tabulky bylo nutné urèit její velikost (poèet platných bitù he¹ovacího klíèe). To v¹ak vedlo dle stavu naplnìní tabulky daty, buï k plýtvání místem (pøi malém mno¾ství ulo¾ených dat) nebo v hor¹ím pøípadì k vytváøení pøíli¹ dlouhých seznamù kolizních blokù a následné ztrátì rychlosti (pøi nadmìrném mno¾ství dat). Tento problém byl èásteènì odstranìn, poskytnutím mo¾nosti reorganizace celé he¹ovací tabulky. Reorganizace ve své podstatì pøehe¹ovávala celou he¹ovací tabulku do tabulky nové, která ji¾ mìla "pøimìøený" rozmìr vzhledem k mno¾ství ulo¾ených záznamù. Zde v¹ak vyvstala nová otázka: "Kdy provádìt danou reorganizaci ?". Jednou z mo¾ností bylo provést ji automaticky, v prùbìhu nìkteré z operací. To by v¹ak vzhledem k èasové nároènosti celé reorganizace vedlo k neúmìrné dobì odezvy. Druhou mo¾ností bylo nechat spu¹tìní reorganizace na vy¹¹í vrstvì, která by danou reorganizaci provedla "na pozadí", tudí¾ bez pøímých konfliktù s ostatními operacemi. To by v¹ak znamenalo zbyteèné pøenesení urèitých implementaèních prvkù tøídy StopList do vy¹¹í vrstvy.
Dùvody popsané v pøedchozím odstavci vedly k tomu, ¾e v druhém "kole" bylo vý¹e popsaná metoda nahrazena he¹ováním dynamickým. To ji¾ samo ze své podstaty vyøe¹ilo øadu problémù. Nedochází k nepøimìøenému hospodaøení s pamìtí. Pøi pøeplnìní jednoho bloku dochází k roz¹tìpení daného bloku, tzn. nevytváøejí se zde spojové seznamy kolizních blokù. Pøi pøeplnìní celé he¹ovací tabulky dochází "pouze" ke zdvojnásobení he¹ovacího adresáøe, co¾ je operace mnohem ménì èasovì nároèná, ne¾li provedení reorganizace pøí pou¾ití pøedchozí metody.
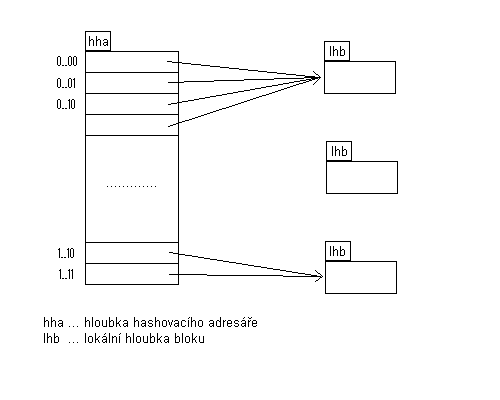
Obrázek 5.2.1.1-1 - struktura
he¹ovacího adresáøe pou¾itého v metodì dynamického
he¹ování
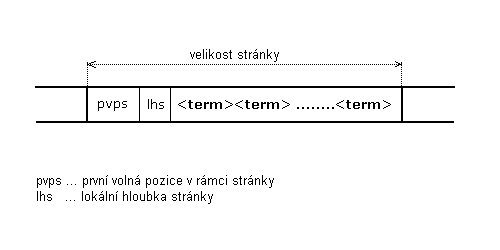
Obrázek 5.2.1.1-2 - struktura stránky
v datovém souboru tøídy StopList
Úkolem objektù typu Books je evidence logických knih dané databáze, vedení informací o knihách a poskytování slu¾eb pro práci s knihami ostatním objektùm databázového stroje. Jde o zaji¹tìní následujících základních operací:
Pøí návrhu reprezentace tøídy Books se vycházelo z pøedpokladu relativnì malého poètu logických knih v rámci jedné databáze. Tento poèet byl odhadnut øádovì na desítky logických knih, z èeho¾ vy¹la mo¾nost umístit v¹echny data do operaèní pamìti. Na tomto pøedpokladu byly do jisté míry navr¾eny datové struktury reprezentující logické knihy v operaèní pamìti a také velice jednoduchá struktura souboru pro jejich ulo¾ení. To, ¾e se pøi návrhu urèitým zpùsobem odhadl pøedpokládaný poèet logických knih, nemá ze následek ¾ádné striktní omezení jejich poètu.
Z charakteru a pøedev¹ím ze znalostí èetností operací bylo mo¾né vznést nároky na datové struktury, které by mìly reprezentovat logické knihy v operaèní pamìti. Hlavním po¾adavkem byl rychlý pøístup k záznamu o knize pøes její jméno a interní identifikaèní èíslo. Vzhledem k pøedpokládanému poètu logických knih, zde byly pou¾ity pro urychlení vyhledání dvì "pole" ukazatelù na jejich záznamy. Ukazatele v tìchto polích jsou setøídìny podle názvu nebo identifikaèního èísla logické knihy, na její¾ záznam ukazují. Po¾adované záznamy jsou poté vyhledávány pomocí tìchto polí binárním zpùsobem.
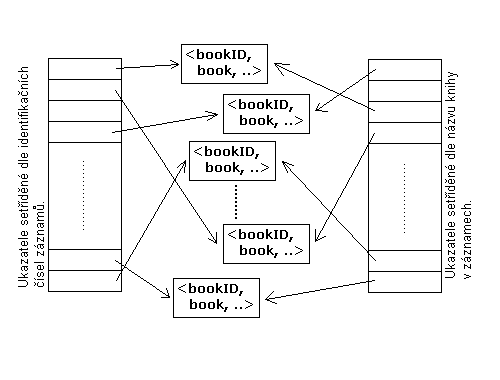
Obrázek 5.2.1.2-1 - datové struktury
reprezentující logické knihy v operaèní pamìti
Úkolem objektù typu Terms je evidence termù dané databáze, vedení statistických informací o termech a poskytování slu¾eb ostatním objektùm databázového stroje. Jde pøedev¹ím o zaji¹tìní následujících základních operací:
Analýzou zpùsobù a èetností pou¾ívání operací s daty objektù typu Terms byl nastolen po¾adavek, na co mo¾ná maximální optimalizaci tìchto operací s ohledem na jejich èasovou nároènost.
Z po¾adavkù kladených na objekty tøídy Terms bylo mo¾no vyèíst urèitou analogii s objekty tøídy StopList. Jednalo se pøedev¹ím o potøebu navrhnout datovou strukturu pro relativnì velké mno¾ství termù, která by dovolovala jejich rychlé vyhledávání a tím umo¾òovala rychlý pøevod termu na jeho interní identifikaèní èíslo. Tato èást byla øe¹ena velice obdobnì jako implementace tøídy StopList. Do¹lo ke stejnému rozhodnutí o pou¾ití he¹ování oproti stromovým reprezentacím. Také zde nastala výmìna "statického" he¹ování za he¹ování dynamické. Jediný rozdíl je v tom, ¾e se do he¹ovací tabulky navíc ukládá vedle termu i jeho interní identifikaèní èíslo, nutné pro vý¹e po¾adovaný pøevod.
Pøí implementaci druhé èásti tøídy Terms bylo vyu¾ito jedné ze základních vlastností termù. A sice, je-li term jednou vlo¾en do databáze, tak je v ní evidován a¾ do konce její existence. To má jeden pøíjemný dùsledek, jsou-li interní identifikaèní èísla pøíøazována vzestupnì, lze jich velice jednodu¹e pou¾it jako indexu do souboru... Tímto byl jemnì naznaèen zpùsob, kterým byla implementována druhá èást tøídy Terms zabývající se vedením statistických informací o termech. Interní identifikaèní èíslo ka¾dého termu slou¾í zároveò jako index do souboru, kde jsou ulo¾eny dal¹í informace o konkrétním termu.
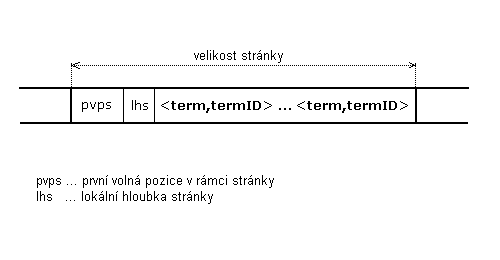
Obrázek 5.2.1.3-1 - struktura stránky
v datovém souboru tøídy Terms
Úkolem objektù typu Indexes je vlastní správa a manipulace s daty dokumentù, které jsou ulo¾eny v databázi. To zahrnuje ulo¾ení jak vlastních dokumentù (ne v¹ak ve zdrojové formì) tak i vedlej¹ích informací o dokumentech (url, název, jméno autora...), jejich opìtovné zpøístupnìní a mo¾nost dal¹í manipulace s ulo¾enými daty. Jde o zaji¹tìní následujících základních operací:
V prvním kroku pøi implementaci tøídy Indexes bylo nutné specifikovat, jaká data a v jaké tvaru budou touto tøídou spravována. S ohledem na po¾adavky, které kladl zvolený vyhledávací model, byly navr¾eny a dále upøesnìny tyto tøi základní druhy dat, které je nutné evidovat pro jednotlivé dokumenty v databázi:
V dal¹í fázi bylo nutné navrhnout optimální zpùsoby reprezentace jednotlivých druhù dat a také metody pro jejích manipulaci. Vzhledem k po¾adovaným operacím a k vlastnostem ukládaných dat a ji¾ se znalostí zpùsobù jejích pou¾ití, byly navr¾eny datové struktury a upøesnìny metody pøístupù k ulo¾eným datùm. Dále bylo navr¾eno následující rozdìlení dat do datových souborù. Nyní si naznaèíme struktury tìchto souborù a tím nastíníme zpùsoby práce s danými daty.
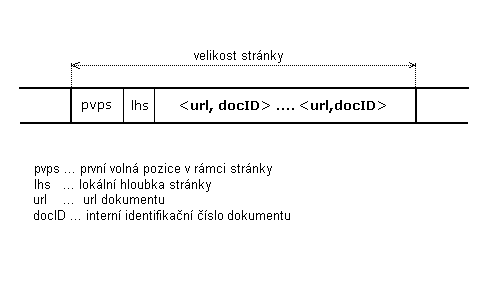
Obrázek 5.2.1.4-1 - struktura
he¹ovací stránky v datovém souboru indurl.dat

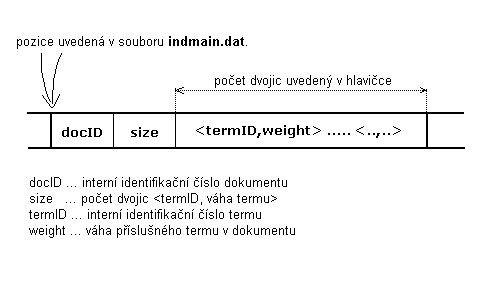
Obrázek 5.2.1.4-2 - struktura
jednotlivých záznamù v souboru indmain.dat
Obrázek 5.2.1.4-3 - popis
reprezentace jednotlivých vektorù dokumentù v souboru indind.dat
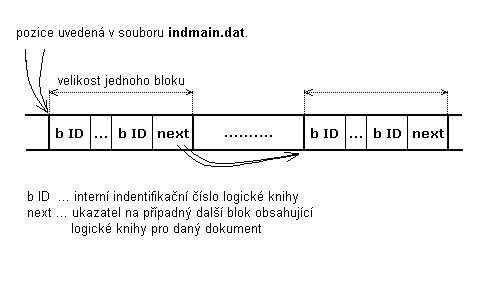
Obrázek 5.2.1.4-4 - struktura
datových blokù v souboru indbooks.dat
Úkolem tøídy Clusters je poskytnout mo¾nost prohledávání ulo¾ených dokumentù a tím nalezení relevantních dokumentù k polo¾enému dotazu. Hlavními po¾adavky jsou pøedev¹ím:
Dále byla po objektech tøídy Clusters po¾adována mo¾nost dynamické práce s dokumenty (neboli zaèleòování nových dokumentù a na druhou stranu i odebíraní dokumentù ru¹ených). Celkovì byly tedy po¾adovány tyto základní operace:
Pro urychlení prohledávání databáze dokumentu, bylo pou¾ito vyhledávání pomocí shlukù. Byly pou¾ity shluky hierarchické, které vedou obecnì k lep¹ím výsledkùm, jak po stránce rychlosti tak i pøesnosti, ne¾li shluky nehierarchické. Ve své podstatì shluky reprezentují urèité uspoøádání dokumentù, které odrá¾í jejich vzájemou podobnost. Jedná se o stromovou strukturu (obecnì n-ární strom), ve které vrcholy pøedstavují jednotlivé dokumenty (pøípadnì seznamy dokumentù). Hrany reprezentují propojení dokumentù dle podobností jejich obsahù (ka¾dý dokument je spojen s dokumentem, který je mu nejpodobnìj¹í). Konkrétnìj¹í popis je uveden na následujících dvou obrázcích.
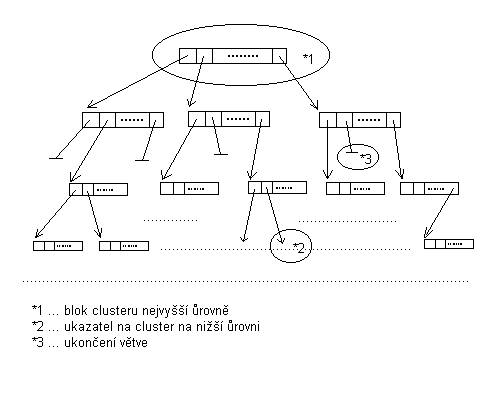
Obrázek 5.2.1.5-1 - logický pohled na
strukturu shlukù ve tøídì Clusters
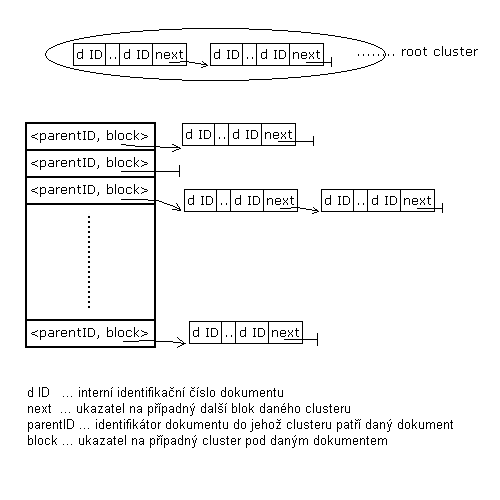
Obrázek 5.2.1.5-2 - reprezentace
shlukù ve tøídì Clusters
| 1999-03-02 | Tomá¹ Foltýnek |