Cvičení: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12.
Cílem tohoto cvičení je představit vám klienta Gitu na příkazové řádce, aby naše komunikace s GitLabem byla mnohem efektivnější. Také si trochu rozšíříme znalosti o skriptování v shellu.
Předstartovní kontrola ⚓
- Rozumíte konceptu standardního vstupu a výstupu a tomu, jak je lze v shellu přesměrovat (a zřetězit).
- Pro zjednodušení spouštění skriptů můžete nastavit správný shebang a spustitelný (executable) bit.
Základy Gitu ⚓
Dosud byla naše práce s GitLabem výhradně skrze GUI. Teď se přesuneme do příkazové řádky, abychom pracovali trochu efektivněji.
Nezapomeňte, že GitLab, je postaven nad Gitem, což je vlastní verzovací systém.
Git má také klienta na příkazové řádce, který umožní stáhnout celý projekt na váš stroj, sledovat v něm změny a ty pak nahrát zpátky na server (v našem případě GitLab, ale není to jediný takový produkt).
Než se pustíme do samotného Gitu, musíme si na něj trochu připravit prostředí.
Výběr editoru ⚓
Git bude často potřebovat spouštět váš editor, základem proto je zajistit, že použije ten, který jste si vybrali.
Následující kroky vysvětlíme podrobněji později, prozatím jen zajistěte, že
přidáte následující řádek na konec souboru ~/.bashrc (mcedit v něm
nahraďte za vámi vybraný editor):
export EDITOR=mcedit
Nyní otevřete nový terminál a spusťte (včetně znaku dolaru):
$EDITOR ~/.bashrc
Pokud jste soubor upravili správně, měli byste jej opět vidět otevřený ve vašem oblíbeném textovém editoru.
Pokud ne, ujistěte se, že jste skutečně upravili svůj soubor .bashrc (ve
svém domovském adresáři) tak, aby obsahoval to, co je uvedeno výše (bez
mezer kolem = atd.).
Příkaz git ⚓
V podstatě všechno okolo Gitu je řízeno příkazem git.
Prvním argumentem je vždy akce – občas se jí říká také podpříkaz –,
kterou chceme provést.
Například, git config nastavuje Git a git commit vytváří nový commit
(verzi).
Vždy je k dispozici nápověda pomocí následujícího příkazu:
git PODPRIKAZ --help
Manuálové stránky jsou dostupné pomocí man git-PODPRIKAZ.
Git má přes 100 podpříkazů. Nepropadejte panice. Začneme s méně než 10 a i poměrně pokročilé funkce nevyžadují znát více než 20 z nich.
Nastavení Gitu ⚓
Jedním z klíčových konceptů v Gitu je, že každý commit (změna) má autora – tedy je známo, kdo jej vytvořil. (Git zvládá i kryptografické podepisováni commitů, takže autorství je nezpochybnitelné, ale tím si teď nebudeme látku komplikovat.)
Potřebujeme tedy Gitu říct, kdo jsme. Následující dva příkazy jsou absolutní minimum, co potřebujete spustit na počítači (nebo účtu), kde chcete pracovat s Gitem.
git config --global user.name "Moje skutečné jméno"
git config --global user.email "můj-email"
Přepínač --global říká, že nastavení má být platné pro všechny Gitové
projekty. Pro lokální změnu můžete spustit stejný příkaz bez tohoto
přepínače uvnitř konkrétního projektu. To může být například užitečné pro
odlišení vaší soukromé a firemní identity.
Poznamenejme, že Git neověřuje správnost e-mailové adresy ani vašeho jména (stejně ani není, jak by mohl). Může zde být tedy cokoliv. Pokud ale použijete svou skutečnou e-mailovou adresu, GitLab dokáže spárovat commity s vaším účtem, atp., což může být užitečné. Rozhodnutí je ale na vás.
Pracovní kopie čili working copy (neboli práce s Gitem lokálně) ⚓
Úplně první operací, kterou je třeba provést, je tzv. klon (clone). Během klonování se vytvoří kopie zdrojáků ze serveru (GitLab) na místní stroj. Server může pro tuto operaci vyžadovat nějaký druh autentizace (ověření uživatele).
Klonování zkopíruje kompletní historii projektu. Všechny commity jsou vidět i v naklonovaném projektu bez potřeby internetového připojení.
Klon se často nazývá pracovní kopií (working copy). Klon je skutečně kopií 1:1 – pokud by někdo projekt vymazal, zdrojové kódy půjde obnovit z klonu (včetně kompletní historie). (To neplatí o Wiki nebo Issues protože ty nejsou Gitem verzované.)
Jak uvidíte, celý projekt z GitLabu se naklonuje jako adresář na vašem disku. Jako obvykle, existují i GUI alternativy k příkazům, které tu budeme ukazovat. My se ale zaměříme jen na CLI variantu.
První klonování (git clone) ⚓
Pro následující příklad použijeme váš repozitář s řešeními ve skupině teaching/nswi177/2026.
Otevřete svůj projekt (v prohlížeči) a klikněte na modré tlačítko
Clone. Měli byste vidět adresy pro Klonování přes SSH a Klonování přes
HTTPS.
Zkopírujte adresu HTTPS a použijte ji v příkazu clone (pochopitelně,
nahraďte LOGIN vaším skutečným loginem, malými písmeny):
git clone https://gitlab.mff.cuni.cz/teaching/nswi177/2026/student-LOGIN.git
Příkaz se vás zeptá na uživatelské jméno a heslo. Jako obvykle v našem GitLabu, použijte prosím přihlašovací údaje do SISu.
Některá prostředí můžou nabízet k použití tzv. klíčenky nebo podobné nástroje na ukládání přihlašovacích údajů. Klidně je používejte. Později se podíváme na to, jak používat SSH a asymetrickou kryptografii pro bezproblémovou práci s projekty Gitu bez potřeby starat se o uživatelská jména a hesla.
Nyní byste měli mít na svém počítači adresář student-LOGIN.
Přesuňte se do něj a podívejte se, jaké soubory tam jsou.
A co skryté soubory?
Odpověď.
Neřekneme-li jinak, všechny příkazy budeme vykonávat uvnitř adresáře
student-LOGIN.
Jakmile je projekt naklonován, můžete začít upravovat soubory. To je naprosto nezávislé na Gitu – dokud Gitu neřeknete, že má něco udělat, vašich souborů se nijak nedotkne.
Jakmile jste dokončili práci na změnách (např. jste opravili chybu), je na čase Gitu říct o nové verzi (revizi).
Provedení změn (git status a git diff) ⚓
Než začnete lokálně měnit jakýkoli soubor, otevřete nový terminál a spusťte
git status. Měli byste vidět něco takového.
$ git status
On branch master
Your branch is up to date with 'origin/master'.
nothing to commit, working tree clean
Nyní provedeme triviální změnu. Otevřete soubor README.md ve svém projektu
(lokálně, tj. ne v uživatelském rozhraní GitLabu v prohlížeči) a přidejte do
něj odkaz na Fórum.
Všimněte si, jak jsou v Markdown vytvořeny odkazy, a přidejte jej jako poslední odstavec.
Po provedení změny spusťte git status. Pozorně si přečtěte celý výstup
tohoto příkazu, abyste pochopili, co vlastně vypisuje.
Vytvořte nový soubor 04/editor.txt a vložte do něj název editoru, který
jste se rozhodli používat (klidně vytvořte adresář 04 v nějakém grafickém
nástroji nebo použijte mkdir 04).
Opět se podívejte, jak git status hlásí tuto změnu v adresáři projektu.
Co jste se naučili? Odpověď.
Spusťte git diff pro zobrazení toho, jak Git sleduje provedené změny.
Zobrazí se seznam změněných souborů (tj. jejich obsah se liší od poslední revize) a také tzv. diff (někdy také nazývaný záplata čili patch), který popisuje změnu.
Diff bude obvykle vypadat nějak takto:
diff --git a/README.md b/README.md
index 39abc23..61ad679 100644
--- a/README.md
+++ b/README.md
@@ -3,3 +3,5 @@
find and check your solution.
Course homepage: https://d3s.mff.cuni.cz/teaching/nswi177/
+
+Forum is at ...
Jak tohle přečíst? Je to obyčejný text, který obsahuje následující:
- soubor, kde ke změně došlo
- kontext změny
- čísla řádků (
-3,3 +3,5) - řádky beze změny (začínají mezerou)
- čísla řádků (
- skutečné změny
- přidané řádky (začínají
+) - odebrané rádky (začínají
-)
- přidané řádky (začínají
Proč je tento výstup vhodný pro změny ve zdrojovém kódu?
Příkaz git diff je taky extrémně užitečný pro ověření, že provedené změny
jsou správné, tím že se zaměřuje jen na kontext změn namísto celých souborů.
Uložení změny natrvalo (git add a git commit) ⚓
Jakmile jste se změnami spokojeni, můžete je připravit k zapsání (staging). Což v Gitovštině znamená, že tyto soubory (jejich současný stav) budou v další verzi. Obvykle budete připravovat všechny změněné soubory. Ale občas je lepší commit rozdělit, protože jste pracovali na dvou věcech a nejdřív commitnete první část a teprve pak tu druhou.
Například jste opravovali chybu, ale také jste našli někde nějaký překlep. Můžete samozřejmě obě opravy přidat najednou do jednoho commitu, ale je mnohem lepší udržet commity malé a cílené na jednu věc. Takže první commit bude Oprava chyby X zatímco druhý bude Oprava preklepu Y.
Což krásně říká, co se vlastně stalo. Je to trochu podobné tomu, jak vytváříte funkce při programování. Jedna funkce má dělat jednu věc (a dělat ji dobře). Jediný commit má zachycovat jedinou změnu.
Teď se připravte na svůj první commit (pro připomenutí: commit je v podstatě
verze nebo pojmenovaný stav projektu) – spusťte git add 04/editor.txt. O
rozšíření souboru README.md se postaráme později.
Jak to změnilo výstup git stutus?
Odpověď.
Poté co připravíte všechny relevantní změny (tj. git addnete všechny
potřebné soubory), můžete vytvořit commit.
Commit vyčistí změny připravené k zapsání a můžete začít opravovat další
chybu :-).
Vytvořte svůj první commit pomocí git commit. Nezapomeňte pro něj použít
výstižnou commit zprávu!
Poznamenejme, že bez přepínačů git commit otevře váš textový
editor. Napište do něj commit zprávu, uložte a editor zavřete. Váš první
commit je tímto dokončen.
Pro krátké commit zprávy můžete použít git commit -m "Fix a typo", kde
celá commit zpráva je dána argumentem přepínače -m (všimněte si uvozovek
kvůli použití mezer).
Jak bude git status vypadat teď? Zamyslete se nad tím před spuštěním
příkazu!
A tohle v podstatě opakujete tak dlouho, dokud máte co měnit. Nezapomeňte, že každý commit by měl zachytit nějaký rozumný stav projektu, ke kterému dává smysl se vracet.
Odeslání změn na server ⚓
Chcete-li nahrát commity (revize) zpět na server, musíte iniciovat takzvaný push. Ten nahraje všechny nové verze (tj. ty, které byly provedeny mezi vaším naklonováním a nyní) zpět na server. Příkaz je poměrně jednoduchý.
git push
Znovu vás požádá o heslo (pokud se vaše desktopové prostředí nerozhodlo znovu použít přihlašovací údaje z dřívějška) a poté byste měli vidět své změny v GitLabu.
Které změny jsou na GitLabu? Odpověď.
Cvičení ⚓
Prohlížení commitů (git log) ⚓
Prozkoumejte, co je v menu Repository -> Commits v GitLabu.
Porovnejte to s výstupem git log a git log --oneline.
Ano, příkazy mohou být i takto jednoduché.
Získání změn ze serveru ⚓
Změňte nadpis v README.md aby také obsahoval for VAŠE JMÉNO.
Tentokrát ale proveďte změnu na GitLabu.
Pro aktualizaci lokálního klonu projektu použijte git pull.
Jak nejsnadněji zjistíte, jestli máte i změnu v souboru README.md
na vašem počítači po provedení git pull?
Odpověď.
Příkaz git pull je opravdu mocný, dokáže začlenit změny, které vznikly v
podstatě ve stejnou dobu na GitLabu a ve vašem lokálním klonu. Porozumění
tomuto procesu ale vyžaduje také znalosti větví, což je mimo rámec tohoto
cvičení.
Práce na více strojích ⚓
Věci se trochu zkomplikují pokud pracujete na více počítačích (např. ráno na školním počítači a večer na vašem notebooku).
Git je dost šikovný na to, aby dokázal sloučit vaše změny z různých míst.
Prozatím je však nejlepší zajistit následující postup, aby se minimalizovalo množství nekompatibilních úprav.
Uvědomte si, že pokud se něco hodně pokazí, můžete vždy provést nový klon do jiného adresáře, zkopírovat soubory ručně a odstranit poškozený klon.
Pokud zapomenete na nějaký synchronizační push/pull při přesunu mezi stroji, tak se mohou objevit problémy. Jsou poměrně jednoduše řešitelné, ale my je budeme probírat až později.
Zatím můžete vždy udělat čistý klon a prostě překopírovat změněné soubory a znovu je commitnout (není to to pravé ořechové, tedy Gitové, ale bude to fungovat).
Něco navíc ⚓
Nepropadejte panice ⚓
Může se zdát, že Gitových příkazů je strašně moc a celý prostup je hrozně složitý. Může to tak vypadat prvních pár dní. Ale jakmile je začnete používat pravidelně, práce s Gitem ustoupí na pozadí a stane se z ní přirozená součást vývojového procesu.
Konec konců, Git se používá pro sledování změn. Důležité změny se odehrávají jinde. Je to jen pomocník, ale zjednoduší nám udržování historie i spolupráci s ostatními vývojáři.
Níže je malý diagram základních operací a jejich pořadí a vztahů.
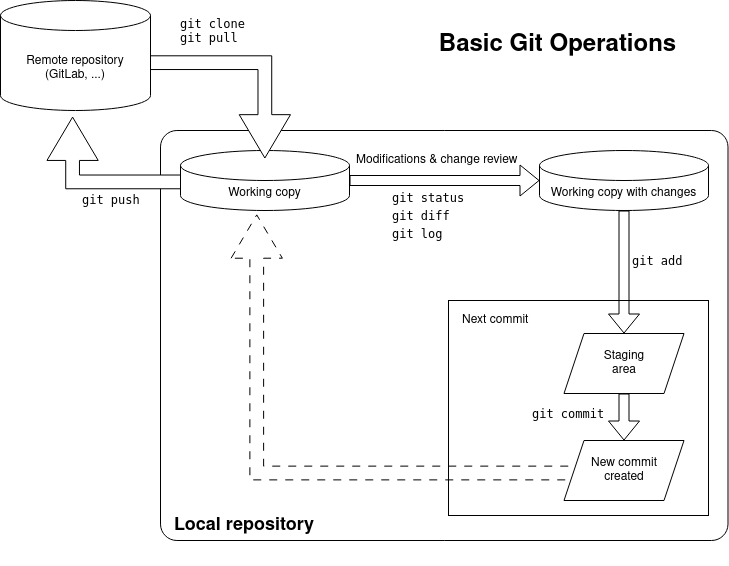
Git: zkontrolujte si, že si pamatujete základní příkazy
Vyberte všechna pravdivá tvrzení.
You need to have enabled JavaScript for the quiz to work.Více o shebangs ⚓
V této části cvičení se trochu vrátíme k tomu předchozímu a rozšíříme si znalosti o shebangs.
Použití jiných interpretrů ⚓
Vytvořte absolutní (!) cestu (nápověda: man 1 realpath) k args.py,
který jsme používali předtím.
Použijte ji jako shebang v jinak prázdném souboru (např. use-args) a označte jej jako spustitelný.
Nápověda.
Poté jej spusťte takto:
./use-args
./use-args first second
Zjistíte, že argument nula teď obsahuje cestu k vašemu skriptu, argument na
pozici jedna obsahuje vnější skript – use-args a až za nimi jsou vlastní
argumenty z příkazové řádky (first a second).
Přestože to může vypadat jako cvičení ve zbytečnostech, jde o demonstraci důležitého principu: Linux je extrémně nakloněn vytváření minijazyků. Potřebujete-li vytvořit interpretr pro svůj vlastní minijazyk, stačí jen zařídit, aby přijímal vstupní jméno souboru jako první argument a voilà, uživatelé v něm můžou psát své vlastní spustitelné soubory.
Jako další příklad si připravte následující soubor, uložte jej jako
experiment (bez přípony) a označte jej jako spustitelný:
#!/bin/sh
echo Hello
Poznamenejme, že jsme se rozhodli znova úplně zahodit příponu, protože uživatele ve skutečnosti nezajímá jaký jazyk jsme použili. A ono je to stejně zachyceno pomocí shebangu.
Nyní změňte shebang na #!/bin/cat a spusťte program znova.
Co se stalo?
Spusťte jej s nějakým argumentem (např. jako ./experiment experiment).
Co se stalo?
Odpověď.
Změňte shebang na /bin/echo. Co se stalo?
Shebang: zkontrolujte si, zda této části rozumíte ⚓
Budeme předpokládat, že my-cat i my-echo jsou spustitelné skripty
v aktuálním adresáři.
my-cat obsahuje jako svůj jediný obsah následující shebang #!/bin/cat a
my-echo obsahuje pouze #!/bin/echo.
Vyberte všechna pravdivá tvrzení.
You need to have enabled JavaScript for the quiz to work.Spouštění testů lokálně ⚓
Protože už víte, co jsou shebang, executable bit, a skripty obecně, máte dostatek znalostí, abyste spustili naše testy lokálně bez potřeby GitLabu.
Mělo by to učinit váš vývoj rychlejší a přirozenější, když nebudete muset čekat na GitLab.
Jednoduše spusťte ./bin/run_tests.sh v kořenovém adresáři vašeho projektu
a prohlédněte si výsledky.
Můžete také spustit jen konkrétní podmnožinu testů.
./bin/run_tests.sh 04
./bin/run_tests.sh 02/architecture
Poznámka: Používate-li vlastní instalaci Linuxu, může být potřeba předem
nainstalovat balíček bats (či bash-bats nebo bats-core).
Psaní vlastních filtrů ⚓
Dokončeme další část průběžného příkladu z předchozího cvičení: chceme vypočítat přenesená data pro každý den a vypsat dny s největším provozem.
Vzhledem k tomu, jak jsme zatím vše poskládali, nám chybí pouze prostřední část roury. Součet velikostí pro jednotlivé dny.
Pro tento účel neexistuje žádné hotové řešení (pokročilí uživatelé mohou
zvážit instalaci termsql), ale my
si vytvoříme vlastní v Pythonu a zapojíme ho do naší pipeline.
Budeme se snažit, aby byl jednoduchý, ale zároveň dostatečně univerzální.
Připomeňme si, že chceme seskupit provoz podle datumů, a proto by náš program měl být schopen provést následující transformaci.
# Vstup
day1 1
day1 2
day2 4
day1 3
day2 1
# Výstup
day1 6
day2 5
Zde je naše verze programu. Všimněte si, že jsme (prozatím) ignorovali ošetření chyb, ale umožnili jsme, aby program mohl být použit jako filtr uprostřed pipeline (tj. číst ze stdin, když nejsou uvedeny žádné argumenty), ale také snadno použitelný pro více souborů.
Ve vlastních filtrech byste měli tento přístup také dodržovat: množství zdrojového kódu, které je třeba napsat, je zanedbatelné, ale uživateli poskytuje flexibilitu při používání.
#!/usr/bin/env python3
import sys
def sum_file(inp, results):
for line in inp:
(key, number) = line.split(maxsplit=1)
results[key] = results.get(key, 0) + int(number)
def main():
sums = {}
if len(sys.argv) == 1:
sum_file(sys.stdin, sums)
else:
for filename in sys.argv[1:]:
with open(filename, "r") as inp:
sum_file(inp, sums)
for key, sum in sums.items():
print(f"{key} {sum}")
if __name__ == "__main__":
main()
S takovým programem můžeme náš skript webové statistiky rozšířit následujícím způsobem.
cat logs/*.csv | cut -d , -f 1,4 | tr ',' ' ' | ./group_sum.py
Pomocí man zjistíte, co dělá tr.
Sami rozšiřte řešení tak, aby se vytiskly pouze 3 nejlepší dny
(sort může řadit řádky i pomocí jiných sloupečků než přes celý řádek).
Odpověď.
Více o přesměrování vstupu a výstupu (“I/O redirection”) ⚓
Základy jsme probrali v minulém cvičení. V tomto textu téma rozšíříme.
Standardní chybový výstup ⚓
Zatímco výstup programu chceme často přesměrovat někam jinam, chyby při běhu programu bychom rádi viděli na obrazovce.
Představte si, že existují soubory one.txt a two.txt, ale
nonexistent.txt v aktuálním adresáři není. Spustíme následující příkaz.
Ne, nepředstavujte si to. Vytvořte soubory one.txt a two.txt, které budou obsahovat slova ONE a TWO, sami v příkazovém řádku.
Nápověda.
Odpověď.
cat one.txt nonexistent.txt two.txt >merged.txt
cat celkem pochopitelně ohlásí chybu - neexistující soubor přečíst
nejde. Kdyby se ale tahle chybová hláška tiskla na stdout, přesměrovala by
se do merged.txt společně s výstupem. To by nebylo úplně praktické.
A proto má každý Linuxový program ještě jeden výstup, standardní chybový výstup, kterému se říká stderr (ze standard error [output]). Stderr je obvykle inicializovaný stejně jako stdout, ale logicky je odlišný. Když přesměrujeme stdout pomocí >, stderr to neovlivní.
V Pythonu je stderr dostupný jako sys.stderr. Opět se chová jako otevřený
soubor.
Naši implementaci můžeme rozšířit tak, aby zpracovávala chyby I/O:
try:
with open(filename, "r") as inp:
sum_file(inp, sums)
except IOError as e:
print(f"Error reading file {filename}: {e}", file=sys.stderr)
Pohled pod kapotu (aneb o deskriptorech souborů) ⚓
Následující text poskytuje přehled souborových deskriptorů, což je abstrakce používaná operačním systémem a aplikacemi při práci s otevřenými soubory. Pochopení tohoto konceptu není pro tento předmět nezbytné, ale jedná se o obecný princip, který je (do určité míry) přítomen ve většině operačních systémů a aplikací (nebo programovacích jazyků).
Pokročilé přesměrování vstupu/výstupu ⚓
Ujistěte se, že máte k dispozici skript group_sum.py.
Připravte si soubory one.txt a two.txt:
echo ONE 1 > one.txt
echo ONE 1 > two.txt
echo TWO 2 >> two.txt
Nyní proveďte následující příkazy.
./group_sum.py <one.txt
./group_sum.py one.txt
./group_sum.py one.txt two.txt
./group_sum.py one.txt <two.txt
Chovalo se to podle vašich očekávání?
Sledujte, jakými cestami (tj. přes které řádky) program prošel při výše uvedených spuštěních.
Přesměrování standardního chybového výstupu ⚓
Chcete-li přesměrovat standardní chybový výstup, můžete opět použít >, ale tentokrát s číslem
2 (které označuje deskriptor souboru stderr).
Proto lze náš příklad cat transformovat do následující podoby, kdy
err.txt bude obsahovat chybovou zprávu a na obrazovku se nic nevypíše.
cat one.txt nonexistent.txt two.txt >merged.txt 2>err.txt
Obecné přesměrování ⚓
Shell nám umožňuje přesměrovat výstupy zcela libovolně pomocí čísel deskriptorů souborů před a za znaménkem větší než.
Například >&2 určuje, že standardní výstup bude přesměrován na standardní chybový výstup.
Může to znít divně, ale vezměme si následující miniskript.
Zde se wget používá ke stažení souboru ze zadané adresy URL.
echo "Downloading tarball for lab 02..." >&2
wget https://d3s.mff.cuni.cz/f/teaching/nswi177/202324/labs/nswi177-lab02.tar.gz 2>/dev/null
Ve skutečnosti chceme skrýt zprávy o průběhu wget a místo nich vypsat naše
zprávy.
Berte to jako ilustraci konceptu, protože wget lze ztišit i pomocí
argumentů příkazového řádku (--quiet).
Někdy chceme přesměrovat stdout a stderr do jednoho souboru.
V těchto situacích by prosté >output.txt 2>output.txt nefungovalo
a musíme použít >output.txt 2>&1 nebo &>output.txt (pro přesměrování obou najednou).
Můžeme použít také 2>&1 >output.txt?
Vyzkoušejte si to sami!
Nápověda.
Důležité speciální soubory ⚓
Již jsme se zmínili, že prakticky vše v Linuxu je soubor. Mnoho speciálních
souborů reprezentujících zařízení se nachází v podadresáři /dev/.
Některé z nich jsou velmi užitečné pro přesměrování výstupu.
Spusťte cat one.txt a přesměrujte výstup na /dev/full a poté na
/dev/null. Co se stalo?
Zejména soubor /dev/null je velmi užitečný, protože jej lze použít v každé
situaci, kdy nás výstup programu nezajímá.
U mnoha programů můžete explicitně určit použití stdin pomocí - (pomlčka)
jako názvu vstupního souboru.
Další možností je explicitně použít /dev/stdin: s tímto názvem můžeme
zprovoznit příklad s group_sum.py:
./group_sum.py /dev/stdin one.txt <two.txt
Pak Python otevře soubor /dev/stdin jako soubor a operační systém (spolu s
shellem) jej skutečně spojí se souborem two.txt.
/dev/stdout lze použít pokud chceme explicitně zadat standardní výstup (to
je užitečné hlavně pro programy pocházející z jiných prostředí, kde není
kladen takový důraz na použití stdout).
Návratová hodnota programu (exit code) ⚓
Doposud naše programy chybu ohlašovaly tak, že zapsaly chybovou zprávu na standardní chybový výstup. To je celkem užitečné pro interaktivní programy, protože uživatel chce vědět, co se pokazilo.
Nicméně pro neinteraktivní použití by bylo nepohodlné rozpoznávat chyby tak, že bychom hledali chybové hlášky na standardním chybovém výstupu. Chybové hlášky se mění, mohou být lokalizované atd. Existuje proto jiný způsob, jak můžeme poznat, zda běh programu skončil chybou či nikoli.
Úspěch či neúspěch poznáme podle exit code. Exit code je celé číslo a na rozdíl od jiných programovacích jazyků indikuje 0 úspěch a libovolný nenulový kód indikuje chybu.
Uhodnete, proč autoři zvolili nulu pro indikaci úspěchu (zatímco v jiných
jazycích je logická hodnota nuly false) a nenulové kódy (jejichž logická
hodnota je obvykle true) byly použity pro chyby? Nápověda: kolika způsoby
může program uspět?
Není-li řečeno jinak, když váš program úspěšně doběhne (například v Pythonu doběhne main a nedojde k vyhození výjimky), exit code by měl být nula.
Chcete-li změnit toto chování, můžete program ukončit s jiným chybovým kódem
jako argumentem funkce exit. V Pythonu je to sys.exit.
Následující příklad je modifikace výše uvedeného souboru group_sum.py,
tentokrát se správným zpracováním exit kódu.
def main():
sums = {}
exit_code = 0
if len(sys.argv) == 1:
sum_file(sys.stdin, sums)
else:
for filename in sys.argv[1:]:
try:
with open(filename, "r") as inp:
sum_file(inp, sums)
except IOError as e:
print(f"Error reading file {filename}: {e}", file=sys.stderr)
exit_code = 1
for key, sum in sums.items():
print(f"{key} {sum}")
sys.exit(exit_code)
Později uvidíme, že různé control-flow konstrukce v shellu (podmínky a smyčky) se řídí právě tím, jaký byl exit code jednotlivých příkazů.
Rychlé selhávání ⚓
Dosud jsme očekávali, že naše shellové skripty nikdy neselžou. Na žádné chyby jsme je ani nepřipravovali.
Časem se podíváme, jak lze exit kódy testovat a používat k lepšímu řízení našich shellových skriptů, ale zatím chceme jen zastavit, kdykoli dojde k nějaké chybě.
To je vlastně docela rozumné chování: obvykle chcete, aby se celý program ukončil, pokud dojde k neočekávanému selhání (místo aby pokračoval s nekonzistentními daty). Podobně jako nezachycená výjimka v Pythonu.
Chcete-li povolit ukončení při chybě, musíte zavolat set -e. V případě
neúspěchu shell ukončí provádění skriptu a skončí se stejným exit kódem jako
neúspěšný příkaz.
Kromě toho obvykle chcete skript ukončit, pokud je použita neinicializovaná
proměnná: to umožňuje set -u. O proměnných si povíme později, ale -e a
-u se obvykle nastavují společně.
A ještě jedno upozornění týkající se roury a úspěšnosti příkazů: úspěšnost
roury je určena jejím posledním příkazem. Příkaz sort /nonexistent | head
je tedy úspěšný příkaz. Chcete-li, aby neúspěch některého příkazu způsobil
neúspěch (celé) pipeline, musíte ve skriptu (nebo shellu) před pipeline
spustit příkaz set -o pipefail.
Obvykle tedy chcete skript začít následující trojicí:
set -o pipefail
set -e
set -u
Mnoho příkazů umožňuje takto slučovat krátké volby (jako -l nebo -h,
které znáte z ls) (všimněte si, že -o pipefail musí být na posledním
místě):
set -ueo pipefail
Navykněte si začínat každý váš skript tímto příkazem.
Pipeline GitLabu budou od této chvíle kontrolovat, zda je tento příkaz součástí vašich skriptů.
Úskalí rour (aneb SIGPIPE) ⚓
Návratové kódy: zkontrolujte si, zda této části rozumíte ⚓
Přizpůsobení shellu ⚓
Již jsme se zmínili, že byste si měli emulátor terminálu přizpůsobit tak, aby se vám pohodlně používal. Koneckonců s ním strávíte minimálně tento semestr a jeho používání by vás mělo bavit.
V tomto cvičení si ukážeme některé další možnosti, jak si zpříjemnit používání shellu.
Aliasy příkazů ⚓
Pravděpodobně jste si všimli, že některé příkazy se stejnými argumenty
voláte často. Jedním z takových příkladů může být ls -l -h, který vypíše
podrobný výpis souborů s použitím velikostí čitelných pro člověka. Nebo
třeba ls -F, který k adresářům připojí lomítko. A pravděpodobně také ls --color.
Shell nabízí vytvoření takzvaných aliasů, kde můžete snadno přidávat nové příkazy, aniž byste museli někde vytvářet plnohodnotné skripty.
Zkuste provést následující příkazy, abyste zjistili, jak lze definovat nový
příkaz l.
alias l='ls -l -h'
l
Můžeme dokonce přepsat původní příkaz, shell zajistí, aby přepisování nebylo rekurzivní.
alias ls='ls -F --color=auto'
Všimněte si, že tyto dva aliasy společně zajišťují, že l bude zobrazovat
názvy souborů barevně.
Kolem znaménka rovná se mezery nepíšeme.
Mezi typické aliasy, které pravděpodobně budete chtít vyzkoušet, patří
následující. Pokud si nejste jisti, k čemu alias slouží, použijte
manuálovou stránku. Všimněte si, že curl se používá k načtení obsahu z
adresy URL a wttr.in je skutečně adresa URL. Mimochodem, tento příkaz
vyzkoušejte, i když nemáte v plánu tento alias používat :-).
alias ls='ls -F --color=auto'
alias ll='ls -l'
alias l='ls -l -h'
alias cp='cp -i'
alias mv='mv -i'
alias rm='rm -i'
alias man='man -a'
alias weather='curl wttr.in'
~/.bashrc ⚓
Výše uvedené aliasy jsou pěkné, ale pravděpodobně je nechcete definovat při
každém spuštění shellu. Většina shellů v Linuxu však má nějaký soubor,
který spustí před vstupem do interaktivního režimu. Obvykle se tento soubor
nachází přímo ve vašem domovském adresáři a je pojmenován podle shellu a
končí na rc (což si můžete zapamatovat jako runtime configuration, čili
běhové nastavení).
Pro Bash, který nyní používáme (pokud používáte jiný shell, pravděpodobně
již víte, kde najdete jeho konfigurační soubory), se tento soubor nazývá
~/.bashrc.
Již jste jej použili při nastavení EDITORu pro Git, ale můžete tam také
přidávat aliasy. V závislosti na vaší distribuci se tam již mohou nacházet
existující aliasy nebo jiné příkazy.
Přidejte tam aliasy, které se vám líbí, uložte soubor a spusťte nový terminál. Zkontrolujte, zda aliasy fungují.
Soubor .bashrc se chová jako skript shellu a nejste omezeni na to, abyste
v něm měli pouze aliasy. Můžete v něm mít prakticky libovolné příkazy,
které chcete spouštět v každém terminálu, který spustíte.
Změna promptu ($PS1) ⚓
Můžete také upravit vzhled promptu. Výchozí nastavení je obvykle rozumné, ale někteří lidé chtějí vidět více informací. Pokud patříte mezi ně, zde jsou podrobnosti (berte je jako přehled, protože přizpůsobení promptu je téma na celou knihu).
Úlohy k ověření vašich znalostí ⚓
Očekáváme, že následující úlohy vyřešíte ještě před příchodem na cvičení, takže se budeme moci o vašich řešeních na cvičení pobavit.
Učební výstupy a kontrola po cvičení ⚓
Tato část podává zhuštěný souhrn základních konceptů a dovedností, které byste měli umět vysvětlit a/nebo použít po každém cvičení. Také obsahují absolutní minimum, které je potřebné pro pochopení navazujících cvičení (a dalších předmětů).
Kontrola po cvičení ⚓
Seznam níže shrnuje nejdůležitější činnosti (akce), které byste měli mít touto dobou provedené. Pokud tomu tak nebude, nebudete moci dokončit další cvičení nebo se tím jeho průchod výrazně zkomplikuje.
- Zvládám ovládat (clone, pull, push, commit) můj Gitový repozitář z příkazové řádky.
Znalosti konceptů ⚓
Znalost konceptů znamená, že rozumíte významu a kontextu daného tématu a jste schopni témata zasadit do většího rámce. Takže, jste schopni …
-
vysvětlit, co je pracovní kopie Gitu (klon, working copy)
-
vysvětlit, proč existují dva druhy výstupu (výstupních proudů): stdout a stderr
-
vysvětlit co je návratový kód programu (exit code)
-
vysvětlit rozdíly a typická využití pro pět hlavních rozhraní, která může využít CLI program: argumenty, stdin, stdout, stderr a návratová hodnota (exit code)
-
volitelné: vysvětlit, co je to deskriptor souboru (z pohledu aplikace, nikoliv OS/kernelu)
Praktické dovednosti ⚓
Praktické dovednosti se obvykle týkají použití daných programů pro vyřešení různých úloh. Takže, dokážete …
-
nastavit informace o autorovi v Gitu
-
nastavit výchozí editor v shellu (nastavení
EDITORv~/.bashrc) -
naklonovat Gitový repozitář v shellu přes HTTPS
-
prohlédnout změny v Gitové pracovní kopii (příkaz
git status) -
vytvořit commit v Gitu z příkazové řádky (příkazy
git addagit commit) -
nahrát nové commity na Git server nebo stáhnout nové do pracovní kopie (za předpokladu projektu s jedním uživatelem, příkazy
git pushagit pull) -
prohlédnout si souhrnné informace o předchozích commitech pomocí
git log -
volitelné: upravit si chování Gitu pomocí aliasů
-
přesměrovat standardní výstup a standardní chybový výstup programu v shellu
-
změnit návratovou hodnotu (exit code) pro Pythoní skripty
-
používat speciální soubor
/dev/null -
používat standardní chybový výstup v Pythonu
-
volitelné: upravit si chování shellu pomocí aliasů
-
volitelné: upravit si konfiguraci shellu pomocí
.bashrca.profileskriptů -
volitelné: upravit si vzhled promptu pomocí proměnné
PS1